В немецком есть несколько глаголов, означающих сделать, достичь, осуществить. Если вы посмотрите в словарь, то глаголы leisten, erledigen, ausführen, vollbringen мало чем отличаются между собой и от общего глагола делать (machen). Попробуем разобраться, какая же между ними разница.Продолжить чтение →
Разница между словами Ding, Sache, Gegenstand, Zeug
Слова Ding, Sache, Gegenstand, Zeug можно перевести на русский словом «вещь», но между ними есть разница в использовании.
Ding — это нечто обычно вещественное, наряду с Sache достаточно универсальное по значению слово. Часто употребляется для вещей, название которых говорящий не может припомнить («штуковина»).Продолжить чтение →
Рецензия на «60-е. Мир советского человека»
Книга Петра Вайля и Александра Гениса мне понравилась. Ожидая, что это будет «легкая» публицистика, вроде истории для масс, я ошибся. Книга оказалась глубже, чем ожидалось. Погружая читателя даже не в мир 60-х, а скорее в душу «шестидесятника», в ход его мыслей, надежды и переживания, книга создает ощущение путешествия даже не в другую эпоху, а в другой ментальный строй общества.Продолжить чтение →
Оптимизация соединения хешированием (hash join) в SQL
Как известно, основными операциями соединения (join) в СУБД, работающей с SQL, являются вложенные циклы (nested loops), операции соединения хешированием (hash joins) и операции сортировки с объединением. Они применяются для всех запросов, содержащих JOIN.
Если одна из соединяемых таблиц небольшая, то планировщик вполне может использовать вложенные циклы для JOIN. При этом берется сначала делается выборка из одной (меньшей) таблицы с наложением ограничивающих фильтров и затем каждая строка этой таблицы сопоставляется с каждой строкой другой таблицы для проверки условий JOIN. Помочь может создание индексов на стобцы как в предикатах соединения (условие в ON), так и в независимых предикатах (условие в WHERE). Понятно, что при достаточно больших размерах таблиц эта процедура все равно будет требовать много времени. Для таких целей и служит hash join.Продолжить чтение →
Ausruhen/entspannen/ausspannen/erholen. Как правильно отдохнуть по-немецки.
В немецком языке есть несколько глаголов, переводимых на русский словом «отдыхать», в некоторых случаях ещё «расслабляться». Однако, обычно не всегда понятно, зачем же их так много и в чём между ними разница. Попробуем разобраться.
В целом, все глаголы: «sich ausruhen», «sich entspannen», «ausspannen», «sich erholen» действительно означают отдых и часто могут быть заменены один на другой без проблем, но есть нюансы.Продолжить чтение →
Алгоритмы поиска
Алгоритмы поиска значения в массиве данных могут не иметь никаких особых требований к входным данным, и такие алгоритмы мы сравним между собой. Если же о входных данных заранее кое-что известно (например, что они упорядочены по алфавиту), то для таких данных могут быть применены другие, более быстродействующие алгоритмы.
Итак, по порядку от самого простого для понимания, с иллюстрацией кодом на JavaScript. Для всех алгоритмов A — массив входных данных, n — его длина, x — значение, которое хотим найти. Нас будет интересовать индекс элемента массива, имеющего искомое значение. Если результат не найден, то возвращается специальное значение «NOT FOUND».
Линейный поиск
Самый простой метод. Перебираем последовательно все элементы массива и каждый сравниваем с искомым значением. Если они равны, то запоминаем индекс. Слабость алгоритма в том, что нам приходится перебирать все элементы, вне зависимости от того, где находится искомый элемент.
Реализация на JavaScript:
// алгоритм
function linearSearch(A,n,x){
var answer = 'not found';
for (var i=0; i<n; i++){
if (A[i]==x){
answer = i;
}
}
return answer;
}
// инициализация
var A = [1,4,6,8,9,54,2,43];
var n = A.length;
var x = 2;
//тест
var res = linearSearch(A,n,x);
alert (res);
Так как алгоритм всегда проходит n итераций, соответственно, можно сказать, что его быстродействие θ(n). (смотри статью про асимптотические нотации).
Усовершенстованный линейный поиск
На самом деле первый алгоритм был несколько надуманным, потому что нет смысла перебирать все оставшиеся значения в массиве, если мы уже нашли искомое. Вот эта идея тут и реализуется.
// алгоритм
function linearSearch(A,n,x){
for (var i=0; i<n; i++){
if (A[i]==x){
return i;
}
}
return 'Not found';
}
// инициализация
var A = [1,4,6,8,9,54,2,43];
var n = A.length;
var x = 2;
//тест
var res = linearSearch(A,n,x);
alert (res);
Поскольку здесь мы не всегда пробегаем по всем значениям, то быстродействие алгоритма (по-научному -его асимптотическая сложность) очень разнится для самого плохого и самого хорошего случаев — от θ(1) до θ(n). Можно сказать, что алгоритм имеет O(n).
Линейный поиск со сторожем (sentinel)
Здесь идея в том, что мы сохраняем последний элемент массива во временной переменной, чтобы на его место записать искомое значение. Это нужно, чтобы вместо цикла for использовать while без риска получить зацикливание, если в массиве не окажется искомой величины. В целом, все эти пляски подразумевают сокращение сравнений в каждой итерации с двух до одного. В описанных выше алгоритмах нам нужно проверить i<n, а затем A[i]=x. В данном же алгоритме проверка одна. Дает ли это выигрыш — зависит от конкретного языка программирования и процессора.
// алгоритм
function linearSearchWithSentinel(A,n,x){
var last = A[n-1];
var i =0;
A[n-1] = x;
while (A[i]!=x){
i++;
}
A[n] = last;
if (i<n || A[n]==x){
return i;
}else{
return 'Not found';
}
}
// инициализация
var A = [1,4,6,8,9,54,2,43];
var n = A.length;
var x = 2;
//тест
var res = linearSearchWithSentinel(A,n,x);
alert (res);
Цена одной итерации здесь может быть ниже, чем у улучшенного линейного поиска, но в асимтотической нотации всё то же самое: от θ(1) до θ(n) и O(n).
Рекурсивный линейный поиск
Тут всё то же самое, только с использованием рекурсии. Просто для иллюстрации.
// алгоритм
function linearSearch(A,n,i,x){
if (i>n){
return 'Not found';
}else if (A[i]==x){
return i;
}else{
return (linearSort(A,n,i+1,x))
}
}
// инициализация
var A = [1,4,6,8,9,54,2,43];
var n = A.length;
var x = 2;
//тест
var res = linearSearch(A,n,0,x);
alert (res);
Двоичный поиск
Этот алгоритм подразумевает, что входной массив уже отсортирован (например, по алфавиту). Только в этом случае можно применять двоичный поиск. Здесь в каждой итерации массив делится на две части, и мы сравниваем срединное значение с искомым. Соответственно, принимаем решение, что может находиться только в левой или только в правой части массива (оказалось больше или меньше границы раздела). Отсекаем ту часть, в которой искомого значения быть не может, таким образом, сразу же уменьшая количество итераций в два раза. Так делаем на каждой следующей итерации, пока «граничное» значение не окажется тем, что мы ищем.
Реализация на JavaScript:
// алгоритм
function binarySearch(A,n,x){
var p=0, r=n-1, q;
while (p<=r){
q = Math.floor((p+r+1)/2);
if (A[q]==x){
return q;
}else if (A[q]>x){
r=q-1;
}else{
p=q+1;
}
}
return 'Not found';
}
// инициализация
var A = [1,4,6,8,9,54,522,4309];
var n = A.length;
var x = 522;
//тест
var res = binarySearch(A,n,x);
alert (res);
Быстродействие (асимптотическая сложность) этого алгоритма O(lb(n)). Здесь lb(n) — это логарифм по основанию 2 (двоичный логарифм).
Рекурсивный двоичный поиск
То же самое, но с применением рекурсии:
// алгоритм
function binarySearch(A,p,r,x){
var q;
if (p>r){
return 'Not found';
}
q = Math.floor((p+r+1)/2);
if (A[q]==x){
return q;
}else if (A[q]>x){
binarySearch(A,p,q-1,x);
}else{
binarySearch(A,q+1,r,x);
}
}
// инициализация
var A = [1,4,6,8,9,54,522,4309];
var n = A.length;
var x = 522;
//тест
var res = binarySearch(A,0,n-1,x);
alert (res);
Стандартные исключения в PHP. Когда какое применить.
Все программисты PHP должны уметь работать с исключениями. Есть много документации и хороших статей по работе с ними. Все используют базовый класс Exception в своем коде, а, дорастая до определенного уровня, начинают плодить собственные классы исключений. Само по себе это делает код более удобочитаемым и управляемым, но часто ведет к необоснованному разрастанию количества классов в коде. Почему-то далеко не все знают и правильно используют стандартные классы исключений PHP, два из которых относятся к самому языку и несколько — к стандартной библиотеке SPL. PHP 7 к этой небольшой коллекции добавил еще несколько классов. В этой статье я хотел описать, в каких случаях применяются все эти классы, чтобы путаницы больше не было.
Полная иерархия исключений в PHP7 имеет такой вид:
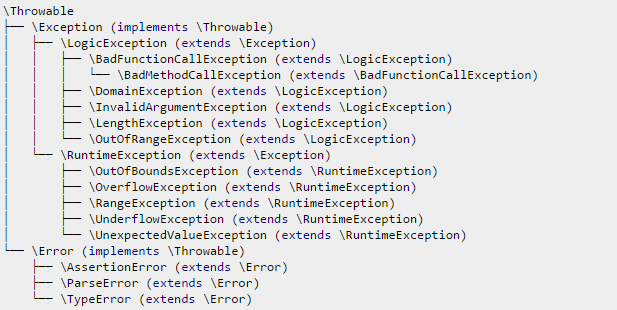
Здесь PHP7 добавил базовый тип Throwable, тип Error и его подтипы AssertionError, ParseError и TypeError. Остальные типы доступны с версии PHP 5.1.0 или еще раньше.
Итак, рассмотрим их по порядку:
Throwable
Throwable — это даже не исключение, а интерфейс, который реализуют все остальные рассматриваемые классы. Добавлен в PHP7.
Exception
Базовый класс для исключений. Стандартная библиотека SPL вводит две группы исключений, два надкласса: для исключений в логике: LogicException и исключений времени исполнении RuntimeException.
LogicException
Используется, когда ваш код возвращает значение, которое не должен возвращать. Часто вызывается при разных багах в коде. Потомки этого класса используются в более специализированных ситуациях. Если ни одна из них не подходит под ваш случай, можно использовать LogicException.
BadFunctionCallException
Используется, когда вызываемой функции физически не существует или когда в вызове используется неверное число аргументов. Редко бывает нужно.
BadMethodCallException
Подкласс BadFunctionCallException. Аналогично ему используется для методов, которые не существют или которым передано неверное число параметров. Всегда используйте внутри __call(), в основном для этого оно и применяется.
Вот пример использования этих двух исключений:
// Для метода в __call
class Foo
{
public function __call($method, $args)
{
switch ($method) {
case 'someExistentClass': /* do something positive... */ break;
default:
throw new BadMethodCallException('Метод ' . $method . ' не может быть вызван');
}
}
}
// процедурный подход function
foo($arg1, $arg2)
{
$func = 'do' . $arg2;
if (!is_callable($func)) {
throw new BadFunctionCallException('Функция ' . $func . ' не может быть вызвана');
}
}
DomainException
Если в коде подразумеваются некие ограничения для значений, то это исключение можно вызывать, когда значение выходит за эти ограничения. Например, у вас дни недели обозначаются числами от 1 до 7, а ваш метод получает внезапно на вход 0 или 9, или, скажем, вы ожидаете число, обозначающее количество зрителей в зале, а получаете отрицательное значени. Вот в таких случаях и вызывается DomainException. Также можно использовать для разных проверок параметров, когда параметры нужных типов, но при этом не проходят проверку на значение. Например,
if ($a>5){
throw new DomainException ("a должно быть меньше 5");
}
InvalidArgumentException
Вызываем, когда ожидаемые аргументы в функции/методе некорректно сформированы. Например, ожидается целое число, а на входе строка или ожидается GET, а пришел POST и т.п.
Пример:
public function foo($number) {
if(!is_numeric($number)) {
throw new InvalidArgumentException('На входе ожидалось число!');
}
}
LengthException
Вызываем, если длина чего-то слишком велика или мала. Например, имя файла слишком короткое или длина массива слишком большая.
RuntimeException
Исключения времени выполнения нужно вызывать, когда код самостоятельно не может справиться с некой ситуацией во время своего выполнения. Подклассы этого класса сужают область применения, но, если ни один из них не подходит для вашей ситуации, смело пользуйтесь этим классом. Вот из каких пяти подклассов вам можно выбирать:
OutOfBoundsException
Вызываем, когда обнаружили попытку использования неправильного ключа, например, в ассоциативном массиве или при реализации ArrayAccess. Используется тогда, когда ошибка не может быть обнаружена до прогона кода. То есть, например, когда то, какие именно ключи будут легитимными, определяется динамически уже во время выполнения.
Вот пример использования в реализации ArrayAccess:
public function offsetGet($offset) {
if(!isset($this->objects[$offset])) {
throw new OutOfBoundsException("Смещение '$offset' вышло из заданного диапазона");
}
return $this->objects[$offset];
}
OutOfRangeException
Используется, когда встречаем некорректный индекс, но на этот раз ошибка должна быть обнаружена ещё до прогона кода, например, если мы пытаемся адресовать элемент массива, который в принципе не поддерживается. То есть если функция, возвращающая день недели по его индексу от 1 до 7, получает внезапно 9, то это DomainException — ошибка логики, а если у нас есть массив с днями недели с индексами от 1 до 7, а мы пытаемся обратиться к элементу с индексом 9, то это уже OutOfRangeException.
OverflowException
Исключение вызываем, когда есть переполнение. Например, имеется некий класс-контейнер, который может принимать только 5 элементов, а мы туда пытаемся записать шестой.
UnderflowException
Обратная OverflowException ситуация, когда, например, класс-контейнер имеет недостаточно элементов для осуществляния операции. Например, когда он пуст, а вы пытаетесь удалить элемент.
RangeException
Вызывается, когда значение выходит за границы некоего диапазона. Похоже на DomainException, но используется при возврате из функции, а не при входе. Если мы не можем вернуть легитимное значение, мы выбрасываем это исключение. То есть, к примеру, функция у вас принимает целочисленный индекс и использует другую функцию, чтоб получить некое значение по этой сущности. Та функция вернула null, но ваша функция не имеет права возвращать Null. В таком случае можно применить это исключение. То есть между ними примерно такая же разница, как между OutOfBoundsException и OutOfRangeException.
UnexpectedValueException
Используется, когда значение выходит из ряда ожидаемых значений. Часто применяется, когда то, что вернулось из вызываемой функции, не соответствует тому, что мы от нее ожидаем в ответе по типу или значению. Сюда не относятся арифметические ошибки или ошибки, связанные с буфером.
Важно, что, в отличие от InvalidArgumentException, здесь мы имеем дело, в основном, с возвращаемыми значениями. Часто мы заранее не можем быть уверены в том, что придет в ответе от функции (особенно сторонней). Скажем, мы используем некую стороннюю функцию, использующую API ВКонтакте, и возвращющую количество постов для пользователя. Она всегда возвращала целое неотрицательное число, и вдруг неожиданно возвращает отрицательное число. Это не соответствует документации. Соответственно, чтобы подстраховаться от таких ситуаций, мы можем проверять результат такого вызова и, если он отличается от ожидаемого, выбрасывать UnexpectedValueException.
Вот пример, когда у нас есть список констант, и функция getValueOfX должна гарантированно возвращать значение одной из них.
const TYPE_FOO = 'foo';
const TYPE_BAR = 'bar';
public function doSomething($y) {
$x = ModuleUsingSomeExternalAPI::getValueOfX($y);
if($x != self::TYPE_FOO && $x != self::TYPE_BAR) {
throw new UnexpectedValueException('Параметр должен быть в виде TYPE_* констант');
}
}
Искусственный пример, в котором есть примеры использования всех классов исключений:
class Example
{
protected $author;
protected $month;
protected $goals = [];
public function exceptions(int $a, int $b): int
{
$valid_a = [7, 8, 9];
if (!is_int($a)) {
throw new InvalidArgumentException("a должно быть целочисленным!");
}
if ($a > 5 || !in_array($a, $valid_a, true)) {
throw new DomainException("a не может быть больше 5");
}
$c = $this->getByIndex($a);
if (!is_int($c)) {
throw new RangeException("c посчитался неправильно!");
} else {
return $c;
}
}
private function getByIndex($a)
{
return ($a < 100) ? $a + 1 : null;
}
public function deleteNextGoal()
{
if (empty($this->goals)) {
throw new UnderflowException("Нет цели, чтобы удалить!");
} elseif (count($this->goals) > 100000) {
throw new OverflowException("Система не может оперериовать больше, чем 100000 целями одновременно!");
} else {
array_pop($this->goals);
}
}
public function getGoalByIndex($i)
{
if (!isset ($this->goals[$i])) {
throw new OutOfBoundsException("Нет цели с индексом $i"); // легитимные значения известны только во время выполнения
} else {
return $this->goals[$i];
}
}
public function setPublicationMonth(int $month)
{
if ($month < 1 || $month > 12) {
throw new OutOfRangeException("Месяц должен быть от 1 до 12!"); // легитимные значения известны заранее
}
$this->month = $month;
}
public function setAuthor($author)
{
if (mb_convert_case($author, MB_CASE_UPPER) !== $author) {
throw new InvalidArgumentException("Все буквы имени автора должны быть заглавными");
} else {
if (mb_strlen($author) > 255) {
throw new LengthException("Поле автор не должно быть больше 255 сиволов!");
} else {
$this->author = $author;
}
}
}
public function __call(string $name, array $args)
{
throw new BadMethodCallException("Метод Example>$name() не существует");
}
}
Error
Добавлено в PHP7 для обработки фатальных ошибок. То есть многие из ошибок, которые раньше приводили к Fatal Error, в PHP7 могут обрабатываться в блоках try/catch. Эти ошибки вызываются самим PHP, неи нужды их вызывать, как Exception. Класс Error имеет три подкласса:
AssertionError
Вызывается, когда условие, заданное методом assert(), не выполняется.
ParseError
Для ошибок парсинга, когда подключаемый по include/require код вызывает ошибку синтаксиса, ошибок функции eval() и т.п.
Пример:
try {
require 'file-with-syntax-error.php';
} catch (ParseError $e) {
// обработка ошибки
}
TypeError
Используется для ошибок несоответствия типов данных. В PHP7 введена опциональная строгая типизация. Вот для поддержки ошибок, связанных с ней, и служит этот класс. Например, если функция ожидает на входе аргумент типа int, а вы ее вызываете со строковым аргументом.
Заключение
Конечно, часто несколько видов ошибок подходят под ситуацию. В этом случае попытайтесь выбрать ту, которая наиболее точно описывает неполадку, ну и которую потом будет проще отлаживать.
Философия архитектуры ООП, SOLID-принципы, Dry, KISS и YAGNI
SOLID — за этой аббревиатурой скрываются 5 базовых принципов ООП, предложенные Робертом Мартином. Следование их духу сделает код легко тестируемым, расширяемым, читаемым и поддерживаемым. Вот шпаргалка по этим принципам:
- Single Responsibility Principle (принцип единственности ответственности) — один класс отвечает за один функционал. Проектируя класс, попробуйте сгруппировать его методы по тем сущностям и процессам, с которыми они работают. Если легко можно выделить несколько групп, то стоит подумать о выделении отдельных сущностей и переносе этих методов в них.
- Open/Closed Principle (принцип открытости/закрытости) — сущности должны быть открыты к расширению, но закрыты — к изменению. То есть, например, класс должен с самого начала проектироваться так, что любое дальнейшее развитие функционала не потребует изменения кода самого этого класса, но позволит расширить функционал с помощью подклассов и т.п.
- Liskov Substitution Principle (принцип подстановки Барбары Лисков) — сущность, использующая объект, который реализует определенный интерфейс, должна иметь возможность использовать другой объект с тем же интерфейсом, даже «не зная» о факте подмены. То есть программируем к интерфейсу, а не к его конкретной реализации.
- Interface Segregation Principle (принцип разделения интерфейса) — клиентский код не должен зависеть от методов, которые не использует. То есть нужно избегать интерфейсов, имеющих много методов — не все из них будут востребованы клиентами. Лучше иметь несколько интерфейсов с небольшим числом методов, чем один — с большим.
- Dependency Inversion Principle (принцип инверсии зависимостей) — модули высшего порядка не должны зависеть от модулей низшего порядка, и те, и другие должны зависеть от абстракций; детали должны зависеть от абстракций, но не наоборот. В общем, класс не должен иметь жестко прописанных в нем зависимостей от объектов других классов, например, через оператор new. Вместо этого зависимости должны быть вынесены из класса, чтобы уменьшить степень связанности кода. Этот принцип реализуется несколькими способами, мы уже писали про самый популярный — внедрение зависимости.
Кроме SOLID, есть еще такие принципы, как:
- KISS — Keep It Simple, Stupid! (делайте вещи проще) — не нужно усложнять дизайн там, где в этом нет необходимости. Чем проще, тем лучше.
- DRY — Don’t Repeat Yourself (не повторяйтесь) — не нужно «изобретать велосипед». Любой функционал в коде должен быть реализован ровно один раз, не говоря уже о том, что copy-paste-кода вообще не должно быть.
- YAGNI — You Ain’t Gonna Need It (вам это не понадобится) — нужно ориентироваться на реальную экономическую необходимость. Если от кода не требуется каких-то вещей, то не нужно их реализовывать. Например, если вы работаете над маленьким сайтом, который надо сдать в сжатые сроки, и который приурочен к одному мероприятию, после чего будет закрыт, то не надо продумывать его архитектуру с точки зрения возможного расширения функционала в будущем. В общем, надо оценивать необходимость своего труда взвешенно.
Как сравнивают быстродействие алгоритмов (асимптотические нотации: о, омега и тета).
Целые книги написаны по теории алгоритмов, но нам, простым смертным, которым не хочется влезать в дебри математики, но всë же любопытно узнать, как сравнивают алгоритмы по эффективности между собой, достаточно знать, что такое асимптотические нотации в общих чертах.
Допустим, у нас есть простейший алгоритм линейного поиска (то есть алгоритм, который перебирает последовательно все элементы массива друг за другом, в ходе этого запоминает индекс того элемента, значение которого равно искомому значению, а завершает работу, когда все элементы массива пройдены. То есть для искомого значения x, массива A с количеством элементов n:
- Присваиваем значение «не найдено» переменной Ответ.
- Для каждого индекса i (от 1 до n): 2А. Если A[i] = x, то присваиваем переменной Ответ значение i.
- Возвращаем значение переменной Ответ
Попробуем подсчитать примерное время выполнения алгоритма в зависимости от n.
Допустим, t1 — время на выполнение шага 1 (выполняется 1 раз), t3 — время на выполнение шага 3 (один раз), t2 — время на проверку условия в шаге 2 (n+1 раз), t2′ — время на инкремент в шаге 2 (выполняется n раз), t2A — время на проверку условия A[i] = x (выполняется n раз) и t2A’ — время на присваивание переменной Ответ = i (выполняется от 0 до n раз в зависимости от содержимого массива, в котором ищем значение).
Итак, в худшем случае имеем:
t1 + t2 * (n+1) + t2′ * n + t2A *n + t2A’ * n + t3 ,
а в лучшем:
t1 + t2 * (n+1) + t2′ * n + t2A *n + t2A’ * 0 + t3
Сгруппируем относительно переменного фактора n (все остальные величины — константы):
(t2 + t2′ + t2A) * n + (t1 + t2 + t3) в лучшем случае и
(t2 + t2′ + t2A + t2A’) * n + (t1 + t2 + t3) в худшем
В обоих случаях у нас многочлен типа a*n + b, где a и b — константы.
Мы видим, что при увеличении n все меньше значения будет играть b.
Не вдаваясь в определение асимптотической нотации, просто покажем, что это такое. У функции, зависящей от количества шагов алгоритма, приведенной к виду многочлена, убираем все младшие члены и коэффициент при старшем члене. То есть a*n + b превращается просто в n. Это называется тета (θ) функцией или нотацией. В нашем случае и в лучшем, и в худшем случае тета будет θ(n). Вообще, асимптотическая нотация для «худшего» случая называется O-нотацией, а для «лучшего» случая — омега (Ω)-нотацией. В нашем случае они совпадают. То есть при O-нотации O(n) мы показываем, что время выполнения алгоритма не может быть больше, чем n, помноженный на коэффициент. Младшими членами, как уже показано, при увеличении количества шагов алгоритма мы можем пренебречь. Например, если у нас функция, описывающая быстродействие алгоритма, вроде такой: t1 * n^2 + t2 * n + t3 , то тета-нотация будет такой: θ(n^2).
В целом, алгоритм с O(1) лучше, чем O(n), который лучше, чем алгоритм с O(n*log n) и т.д.
При сравнении конкретных алгоритмов надо помнить, что при малых значениях n нет смысла использовать эти нотации для сравнения, потому что в этом случае младшие члены многочленов могут быть даже больше, чем старшие. Однако, обычно алгоритмы все же используются для обработки больших объемов данных, и именно тогда имеет значение их эффективность.
Есть хорошая шпаргалка по эффективности основных алгоритмов и по различным видам асимптотических нотаций.
Различия между on и where в SQL
Рассмотрим примеры:
select id, name from tbl_users u join tbl_groups g on u.group_id = g.id where g.name= 'some group'
и
select id, name from tbl_users u join tbl_groups g on u.group_id = g.id and g.name= 'some group'
Что будет результатом выполнения зарпосов? Все пользователи (id и имя), относящиеся к группе ‘some group’.
На первый взгляд разницы между двумя этими запросами нет, но будут ли одинаковыми результаты следующих запросов, использующих left join?
select u.id, rent from tbl_users u left join user_payment p on p.user_id = u.id where p.type= 'fine' or p.type is null
и
select u.id, rent from tbl_users u left join user_payment p on p.user_id = u.id and (p.type= 'fine' or p.type is null)
Нет, не будут. В первом случае мы получим всех пользователей, которые совершили платеж типа ‘fine’ и тех, кто ни разу не совершал никакого платежа. Во втором — всех пользователей, независимо от того, совершали ли они какие-то платежи. При этом во второй выборке поле rent будет заполнено платежом типа fine, если найдется такая запись в таблице user_payment, иначе — null.
Надо помнить, что условие в on относится только к операции join, тогда как в where — ко всему запросу целиком. Соответственно,
- если не удовлятворяется условие по on, то мы все равно получаем все строки из первой таблицы, а отсутствующие данные из второй таблицы дополняются Null.
- Если же не удовлетворяется условие по where, то мы такие строки в выборке вообще не получаем.