Среди множества сайтов, посвященных веб-разработке в интеренете, есть много отличных справочных пособий, руководств и т.п. В данном обзоре я приведу несколько отличных сайтов, которыми пользуюсь сам. Здесь не будет абсолютно необходимых и известных всем php.net, stackoverflow.com и т.п., зато будут, может быть, менее известные сайты, но с большим уклоном не на справочность, а на обучение, и написанных понятным языком без всякой шелухи.
1 W3schools.com
 Этот сайт особенно полезен для начинающих разработчиков. Там коротко и понятно объясняются основные концепции HTML, CSS, JavaScript, PHP, XML и многих других веб-технологий. Более продвинутые разработчики, могут использовать сайт в своей работе как краткую справку в первую очередь по клиентским технологиям: HTML, CSS, JavaScript. Если забыли, какие значения может принимать атрибут определенного тега, если нужно сообразить, как написать сложный CSS-селектор, если нужно проверить, будет ли поддерживать определенное свойство конкретный браузер, то этот сайт будет полезен.
Этот сайт особенно полезен для начинающих разработчиков. Там коротко и понятно объясняются основные концепции HTML, CSS, JavaScript, PHP, XML и многих других веб-технологий. Более продвинутые разработчики, могут использовать сайт в своей работе как краткую справку в первую очередь по клиентским технологиям: HTML, CSS, JavaScript. Если забыли, какие значения может принимать атрибут определенного тега, если нужно сообразить, как написать сложный CSS-селектор, если нужно проверить, будет ли поддерживать определенное свойство конкретный браузер, то этот сайт будет полезен.
2 Bonsaiden
Отличное краткое онлайн-руководство по ключевым концепциям JavaScript. Хотите понять, как устроены замыкания, на что ссылается this или как используется прототип, то лучшего подспорья не найти. Я бы оценил руководство, как хорошее среднее звено между сайтами для начинающих и сложными статьями или учебниками по узким вопросам.
3 Phptherightway.com
 Сайт для разработчиков PHP, на котором группой авторитетных программистов собраны лучшие практики и рекомендации по актуальным вопросам. Оформление кода, документирование, доступ к БД, шаблонизация, безопасность, тестирование, кеширование, разные вопросы непосредственно программирования — только некоторые из тем, освещенных там. Сайт достаточно авторитетен, чтобы пользоваться им как руководством, и практики, освещенные там, являются результатом долгих обсуждений и консенсуса в среде разработчиков.
Сайт для разработчиков PHP, на котором группой авторитетных программистов собраны лучшие практики и рекомендации по актуальным вопросам. Оформление кода, документирование, доступ к БД, шаблонизация, безопасность, тестирование, кеширование, разные вопросы непосредственно программирования — только некоторые из тем, освещенных там. Сайт достаточно авторитетен, чтобы пользоваться им как руководством, и практики, освещенные там, являются результатом долгих обсуждений и консенсуса в среде разработчиков.
4 Survive The Deep End: PHP Security
Этот сайт — онлайн книга также о PHP, точнее, о вопросах безопасности в PHP. Коротко и ясно там и про валидацию входных данных, и про кросс-сайтовые атаки, и про инъекции, и про то, как от предусмотреть защиту от возможных атак в коде.
5 Sourcemaking.com
Паттерны проектирования (в первую очередь PHP), антипаттерны, советы по рефакторингу и учебник по UML — вот что такое этот сайт. Темы раскрыты максимально подробно и понятно. По сути сайт — это полноценный онлайн-учебник по указанным аспектам архитектуры PHP-приложений (вообще, не только PHP, но и C#, Java и т.п., однако веб-разработчику интересен в первую очередь PHP). Для каждого паттерна проектирования есть примеры на PHP.
6 Use-the-index-luke.com
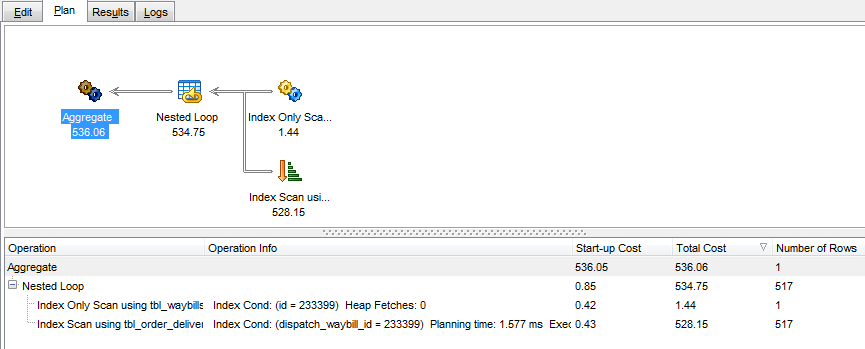
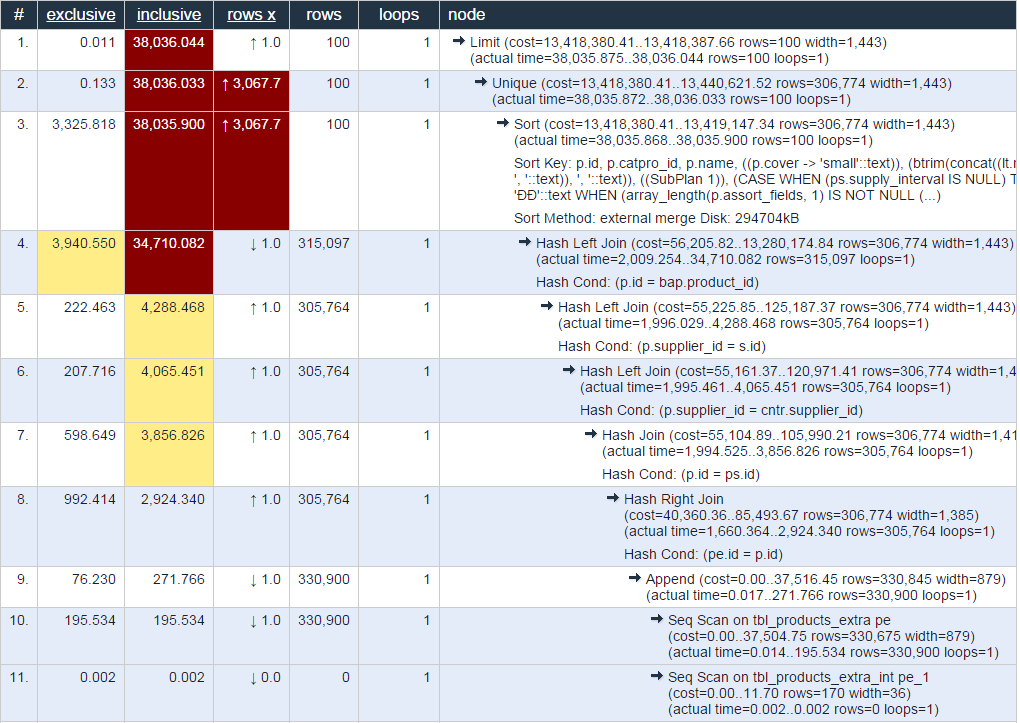
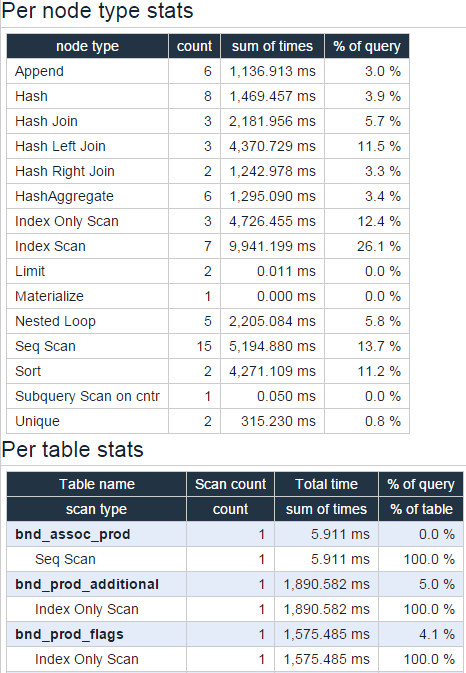
 Веб-разработчику приходится работать и с базами данных. Понятно, что по языку SQL существует много ресурсов, а по конкретным СУБД лучше использовать оригинальную документацию, но есть задачи, которые требуют глубокого понимания некоторых механизмов работы СУБД. Этот сайт доступным языком рассказывает об индексах, как они учстроены и как нужно писать и оптимизировать запросы. Это, пожалуй, единственный специализированный сайт такого рода, который нацелен именно на людей, пишущих запросы к БД, а не на системных админинстраторов. Что важно, в статьях много примеров, и каждый пример есть для каждой из следующих СУБД: DB2, MySQL, Oracle, PostgreSQL, SQL Server.
Веб-разработчику приходится работать и с базами данных. Понятно, что по языку SQL существует много ресурсов, а по конкретным СУБД лучше использовать оригинальную документацию, но есть задачи, которые требуют глубокого понимания некоторых механизмов работы СУБД. Этот сайт доступным языком рассказывает об индексах, как они учстроены и как нужно писать и оптимизировать запросы. Это, пожалуй, единственный специализированный сайт такого рода, который нацелен именно на людей, пишущих запросы к БД, а не на системных админинстраторов. Что важно, в статьях много примеров, и каждый пример есть для каждой из следующих СУБД: DB2, MySQL, Oracle, PostgreSQL, SQL Server.